GPU Monitoring and Optimizing
This document provides a comprehensive guide to monitoring GPU usage and optimizing GPU performance on the HCC. Its goal is to help you identify GPU bottlenecks in your jobs and offer instructions for optimizing GPU resource utilization.
Table of Contents¶
- Measuring GPU Utilization in Real Time
- Logging and Reporting GPU Utilization
- nvidia-smi
- TensorBoard
- How to Improve Your GPU Utilization
- Maximize Parallelism
- Memory Management and Optimization
- Minimize CPU-GPU Memory Transferring Overhead
- How to Improve Your GPU Utilization for Deep Learning Jobs
- Maximize Batch Size
- Optimize Data Loading and Preprocessing
- Optimize Model Architecture
- Common Oversights
- Overlooking GPU-CPU Memory Transfer Costs
- Not Leveraging GPU Libraries
- Not Handling GPU-Specific Errors
- Neglecting Multi-GPU Scalability
Measuring GPU Utilization in Real Time¶
You can use the nvidia-smi command to monitor GPU usage in real time. This tool provides details on GPU memory usage and utilization. To monitor a job, you need access to the same node where the job is running.
Warning
If the job to be monitored is using all available resources for a node, the user will not be able to obtain a simultaneous interactive job.
Once the job has been submitted and is running, you can request an interactive session on the same node using the following srun command:
srun --jobid=<JOB_ID> --pty bash
where <JOB_ID> is replaced by the job ID for the monitored job as assigned by SLURM.
After getting access to the node, use the following command to monitor GPU performance in real time:
watch -n 1 nvidia-smi
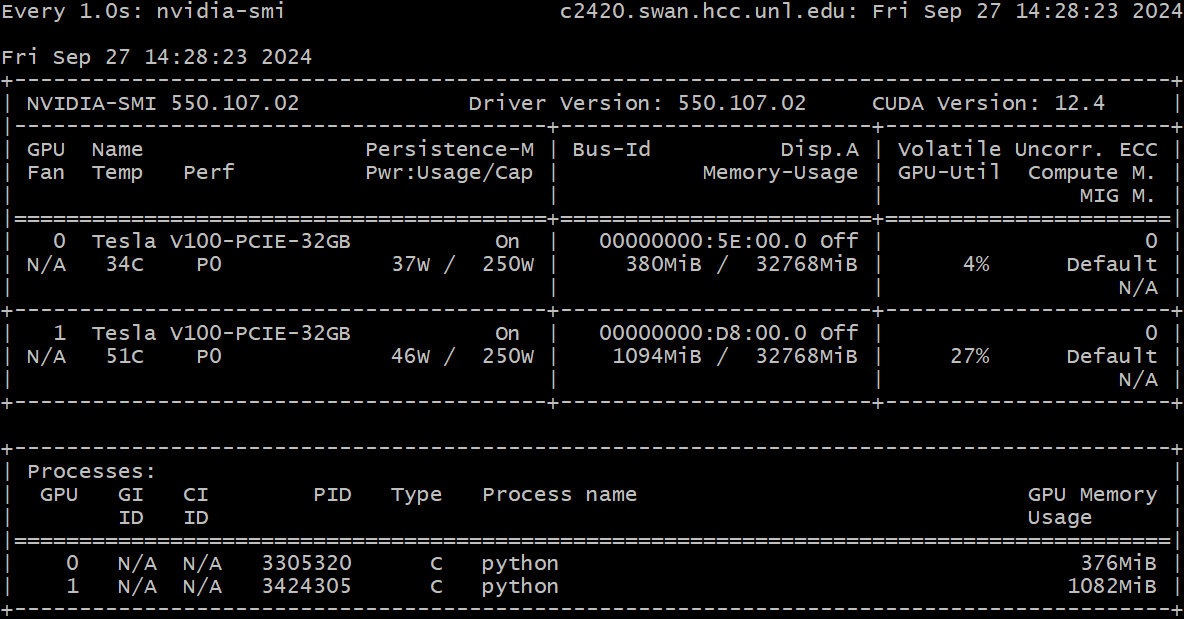
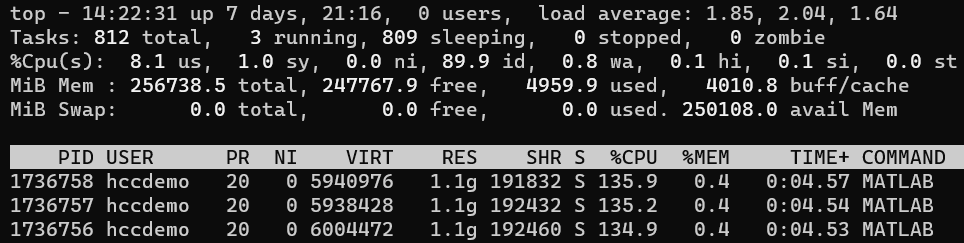
Note that nvidia-smi only shows the process ID (PID) of the running GPU jobs. If multiple jobs are running on the same node, you'll need to match the PID to your job using the top command. Start the top command as follows:
top
In top, the PID appears in the first column, and your login ID is shown in the USER column. Use this to identify the process corresponding to your job.
Logging and Reporting GPU Utilization¶
nvidia-smi¶
You can use nvidia-smi to periodically log GPU usage in CSV files for later analysis. This is convenient to be added in the SLURM submit script instead of running it interactively as shown above. To do this, wrap your job command with the following in your SLURM submission script. This will generate three files in your $WORK directory:
gpu_usage_log.csv: contains overall GPU performance data, including GPU utilization, memory utilization, and total GPU memory.pid_gpu_usage_log.csv: logs GPU usage for each process, including the process ID (PID) and GPU memory used by each process. Note that, to match a specific PID with overall GPU performance in the generated file, use the GPU bus ID.pid_lookup.txt: provides the process ID to help identify which one corresponds to your job in the GPU records.
Note that the job ID will be appended to the file names to help match the logs with your specific job.
curpath=`pwd`
cd $WORK
nohup nvidia-smi --query-gpu=timestamp,index,gpu_bus_id,utilization.gpu,utilization.memory,memory.used,memory.total --format=csv -f gpu_usage_log.csv-$SLURM_JOB_ID -l 1 > /dev/null 2>&1 &
gpumonpid=$!
nohup nvidia-smi --query-compute-apps=timestamp,gpu_bus_id,pid,used_memory --format=csv -f pid_gpu_usage_log-$SLURM_JOB_ID.csv -l 1 > /dev/null 2>&1 &
gpumonprocpid=$!
nohup top -u <LOGIN-ID> -d 10 -c -b -n 2 > pid_lookup-$SLURM_JOB_ID.txt 2>&1 &
cd $curpath
<YOUR_JOB_COMMAND>
kill $gpumonpid
kill $gpumonprocpid
where <LOGIN-ID> is replaced by your HCC login ID and <YOUR_JOB_COMMAND> is replaced by your job command. A complete example SLURM submit script that utilizes this approach can be found here.
TensorBoard¶
If your deep learning job utilizes libraries such as TensorFlow or PyTorch, you can use TensorBoard to monitor and visualize GPU usage metrics, including GPU utilization, memory consumption, and model performance. TensorBoard provides real-time insights into how your job interacts with the GPU, helping you optimize performance and identify bottlenecks.
To monitor GPU usage with TensorBoard, refer to the specific instructions of TensorFlow or PyTorch to enable logging with TensorBoard in your job code:
TensorFlow- TensorFlow Profiler GuidePyTorch- PyTorch Profiler with TensorBoard
On Swan, TensorBoard is available as Open OnDemand App.
How to Improve Your GPU Utilization¶
Improving GPU utilization means maximizing both the computational and memory usage of the GPU to ensure your program fully utilizes GPU's processing power. Low utilization can result from various bottlenecks, including improper parallelism, insufficient memory management, or CPU-GPU communication overhead.
Maximize Parallelism¶
The GPU is powerful because its parallel processing capabilities. Your job should leverage parallelism effectively:
- Optimize grid and block dimensions: configure your thread and block settings to match your job's data size to fully utilize GPU cores.
- Occupancy: use tools like CUDA’s occupancy calculator to determine the best number of threads per block that maximizes utilization.
- Streamlining parallel tasks: CUDA streams can be used to execute multiple operations concurrently. This allows for overlapping computation on the GPU with data transfers, improving efficiency.
Memory Management and Optimization¶
Use Shared Memory Effectively¶
Shared memory is a small, high-speed memory located on the GPU. It can be used to reduce global memory access latency by storing frequently used data. Use shared memory to cache data that is repeatedly accessed by multiple threads.
Avoid Memory Divergence¶
Memory divergence occurs when threads in a warp access non-contiguous memory locations, resulting in multiple memory transactions. To minimize divergence:
- Align memory access: ensure that threads in a warp access contiguous memory addresses.
- Use memory coalescing: organize memory access patterns to allow for coalesced memory transactions, reducing the number of memory accesses required.
Reduce Memory Footprint¶
Excessive memory use can lead to spills into slower global memory. Minimize your program’s memory footprint by:
- Freeing unused memory: always release memory that is no longer needed.
- Optimizing data structures: use more compact data structures and reduce precision when possible (e.g., using floats instead of doubles).
Minimize CPU-GPU Memory Transferring Overhead¶
Data transfer between the CPU and GPU is often a bottleneck in scientific programs. It is essential to minimize these transfers to improve overall GPU performance. Here are some tips:
- Batch data transfers: transfer large chunks of data at once rather than sending small bits frequently.
- Asynchronous memory transfers: use non-blocking memory transfer operations (e.g., cudaMemcpyAsync for CUDA) to allow computation and data transfer to overlap.
- Pin memory: use pinned (page-locked) memory on the CPU for faster transfer of data to and from the GPU.
How to Improve Your GPU Utilization for Deep Learning Jobs¶
In deep learning, GPUs are a key component for accelerating model training and inference due to their ability to handle large-scale matrix operations and parallelism. Below are tips to maximize GPU utilization in deep learning jobs.
Maximize Batch Size¶
Batch size refers to the number of training samples processed simultaneously. Larger batch sizes improve GPU utilization by increasing the workload per step. The batch size should fit within the GPU’s memory constraints:
- Larger batch sizes: result in better utilization but require more memory.
- Gradient accumulation: if GPU memory limits are reached, you can accumulate gradients over several smaller batches before performing a parameter update, effectively simulating larger batch sizes.
Optimize Data Loading and Preprocessing¶
Data loading can become a bottleneck, causing the GPU to idle while waiting for data.
- Parallel data loading: load data in parallel to speed up (e.g., using libraries like PyTorch’s
DataLoaderor TensorFlow’stf.datapipeline). - Prefetch data: use techniques (e.g., double-buffering) to overlap data preprocessing and augmentation with model computation, enabling data to be fetched in advance. This helps reduce the GPU idle time.
Optimize Model Architecture¶
Model architecture impacts the GPU utilization. Here are some optimization tips:
- Reduce memory bottlenecks: avoiding excessive use of operations that cause memory overhead (e.g., deep recursive layers).
- Imporve parallelism: using layers that can exploit parallelism (e.g., convolutions, matrix multiplications).
- Prune unnecessary layers: prune your model by removing layers or neurons that don’t contribute significantly to the output, reducing computation time and improving efficiency.
Common Oversights¶
Overlooking GPU-CPU Memory Transfer Costs¶
Memory transfers between CPU and GPU can be expensive, and excessive data movement can reverse the performance gains offered by parallelism on GPU.
Not Leveraging GPU Libraries¶
There are highly optimized libraries available for GPU-accelerated algorithms, such as linear algebra and FFTs. Always check for these libraries before implementing your own solution, as they are often more efficient and reliable.
Not Handling GPU-Specific Errors¶
GPU computation errors can lead to silent failures, making debugging extremely difficult. For example, insufficient memory on the GPU or illegal memory access can go undetected without proper error handling.
Neglecting Multi-GPU Scalability¶
Many programs are initially designed for single-GPU execution and lack support for multiple GPUs. Make sure your program is optimized for multi-GPU execution before scaling up to request multiple GPU resources.