Job Dependencies
The job dependency feature of SLURM is useful when you need to run multiple jobs in a particular order. A standard example of this is a workflow in which the output from one job is used as the input to the next. Rather than continually check to see if one job has ended and then manually submit the next, all the jobs in the workflow can be submitted at once. SLURM will then run them in the proper order based on the conditions supplied.
Syntax¶
The basic syntax is to include the -d option with the sbatch command
for a new submission to indicate it depends on another job. You must
also supply the condition and job id upon which it depends. SLURM
supports several possible conditions; see the sbatch
man page
for all the options. The example here uses afterok, which instructs
SLURM to only run the submitted job after the dependency job has
terminated without error (exit code 0).
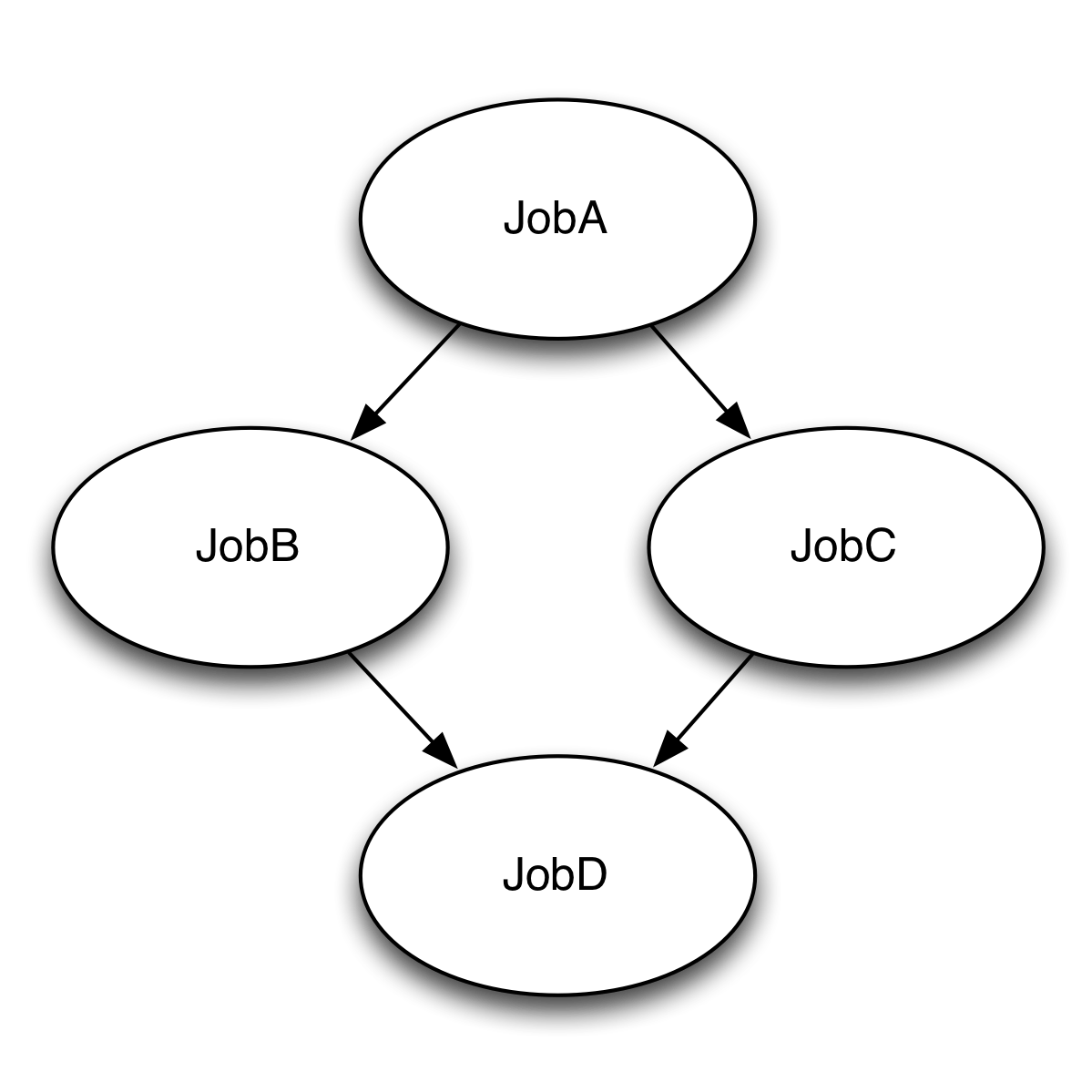
This example is usually referred to as a "diamond" workflow. There are 4 jobs total; the jobs are labeled A through D. Job A runs first. Jobs B and C both depend on Job A completing before they can run. Job D then depends on Jobs B and C completing.
The SLURM submit files for each step are below.
JobA.submit
#!/bin/bash
#SBATCH --job-name=JobA
#SBATCH --time=00:05:00
#SBATCH --ntasks=1
#SBATCH --output=JobA.stdout
#SBATCH --error=JobA.stderr
echo "I'm job A"
echo "Sample job A output" > jobA.out
sleep 120
JobB.submit
#!/bin/bash
#SBATCH --job-name=JobB
#SBATCH --time=00:05:00
#SBATCH --ntasks=1
#SBATCH --output=JobB.stdout
#SBATCH --error=JobB.stderr
echo "I'm job B"
echo "I'm using output from job A"
cat jobA.out >> jobB.out
echo "" >> jobB.out
echo "Sample job B output" >> jobB.out
sleep 120
JobC.submit
#!/bin/bash
#SBATCH --job-name=JobC
#SBATCH --time=00:05:00
#SBATCH --ntasks=1
#SBATCH --output=JobC.stdout
#SBATCH --error=JobC.stderr
echo "I'm job C"
echo "I'm using output from job A"
cat jobA.out >> jobC.out
echo "" >> jobC.out
echo "Sample job C output" >> jobC.out
sleep 120
JobD.submit
#!/bin/bash
#SBATCH --job-name=JobD
#SBATCH --time=00:05:00
#SBATCH --ntasks=1
#SBATCH --output=JobD.stdout
#SBATCH --error=JobD.stderr
echo "I'm job D"
echo "I'm using output from jobs B and C"
cat jobB.out >> jobD.out
echo "" >> jobD.out
cat jobC.out >> jobD.out
echo "" >> jobD.out
echo "Sample job D output" >> jobD.out
sleep 120
To start the workflow, submit Job A first:
Submit Job A
[demo01@login.swan demo01]$ sbatch JobA.submit
Submitted batch job 666898
Now submit jobs B and C, using the job id from Job A to indicate the dependency:
Submit Jobs B and C
[demo01@login.swan demo01]$ sbatch -d afterok:666898 JobB.submit
Submitted batch job 666899
[demo01@login.swan demo01]$ sbatch -d afterok:666898 JobC.submit
Submitted batch job 666900
Finally, submit Job D as depending on both jobs B and C:
Submit Job D
[demo01@login.swan demo01]$ sbatch -d afterok:666899:666900 JobD.submit
Submitted batch job 666901
Running squeue will now show all four jobs. The output from squeue
will also indicate that Jobs B, C, and D are in a pending state because
of the dependency.
Squeue Output
[demo01@login.swan demo01]$ squeue -u demo01
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
666899 batch JobB demo01 PD 0:00 1 (Dependency)
666900 batch JobC demo01 PD 0:00 1 (Dependency)
666901 batch JobD demo01 PD 0:00 1 (Dependency)
666898 batch JobA demo01 R 0:52 1 c2409
As the each job completes successfully, SLURM will run the job(s) in the workflow as resources become available.