Submitting GPU Jobs
Available GPUs¶
Swan has two types of GPUs available in the gpu partition. The
type of GPU is configured as a SLURM feature, so you can specify a type
of GPU in your job resource requirements if necessary.
| Description | SLURM Feature | Available Hardware |
|---|---|---|
| Tesla V100, with 10GbE | gpu_v100 | 1 node - 4 GPUs with 16 GB per node |
| Tesla V100, with OPA | gpu_v100 | 21 nodes - 2 GPUs with 32GB per node |
| Tesla V100S | gpu_v100 | 4 nodes - 2 GPUs with 32GB per node |
| Tesla T4 | gpu_t4 | 12 nodes - 2 GPUs with 16GB per node |
| NVIDIA A30 | gpu_a30 | 5 nodes - 2x2 GPUs and 3x4 GPUs with 24GB per node |
| NVIDIA L40S | gpu_l40s | 11 nodes - 4 GPUs with 48GB per node |
| NVIDIA H200 | gpu_h200 | 4 nodes - 2 GPUs with 140GB per node |
Specifying GPU memory (optional)¶
You may optionally specify a GPU memory amount via the use of an additional feature statement. The available memory specifcations are:
| Description | SLURM Feature |
|---|---|
| 12 GB RAM | gpu_12gb |
| 16 GB RAM | gpu_16gb |
| 24 GB RAM | gpu_24gb |
| 32 GB RAM | gpu_32gb |
| 48 GB RAM | gpu_48gb |
Specifying advanced GPU features (optional)¶
You may optionally request GPU nodes with additional advanced features, such as GPU nodes with different Compute Capability needed for different scientific applications and nodes with double-precision floating-point units. The available SLURM features are:
| Description | SLURM Feature |
|---|---|
| CUDA GPU Compute Capability 6.0 | gpu_cc_6.0 |
| CUDA GPU Compute Capability 6.1 | gpu_cc_6.1 |
| CUDA GPU Compute Capability 7.0 | gpu_cc_7.0 |
| CUDA GPU Compute Capability 7.5 | gpu_cc_7.5 |
| CUDA GPU Compute Capability 8.0 | gpu_cc_8.0 |
| CUDA GPU Compute Capability 8.6 | gpu_cc_8.6 |
| CUDA GPU Compute Capability 8.9 | gpu_cc_8.9 |
| CUDA GPU Compute Capability 9.0 | gpu_cc_9.0 |
| Hardware accelerated 64-bit floating point units | gpu_fp64 |
Requesting GPU resources in your SLURM script¶
To run your job on the next available GPU regardless of type, add the following options to your srun or sbatch command:
--partition=gpu --gres=gpu
To run on a specific type of GPU, you can constrain your job to require a feature. To run on P100 GPUs for example:
--partition=gpu --gres=gpu --constraint=gpu_p100
Note
You may request multiple GPUs by changing the--gres value to
--gres=gpu:2. Note that this value is per node. For example,
--nodes=2 --gres=gpu:2will request 2 nodes with 2 GPUs each, for a
total of 4 GPUs.
The GPU memory feature may be used to specify a GPU RAM amount either independent of architecture, or in combination with it.
For example, using
--partition=gpu --gres=gpu --constraint=gpu_16gb
will request a GPU with 16GB of RAM, independent of the type of card
(P100, T4, etc.). You may also request both a GPU type and
memory amount using the & operator (single quotes are used because
& is a special character).
For example,
--partition=gpu --gres=gpu --constraint='gpu_32gb&gpu_v100'
will request a V100 GPU with 32GB RAM.
Warning
You must verify the GPU type and memory combination is valid based on the
available GPU types..
Requesting a nonexistent combination will cause your job to be rejected with
a Requested node configuration is not available error.
Requesting GPU Resources in Open OnDemand Session¶
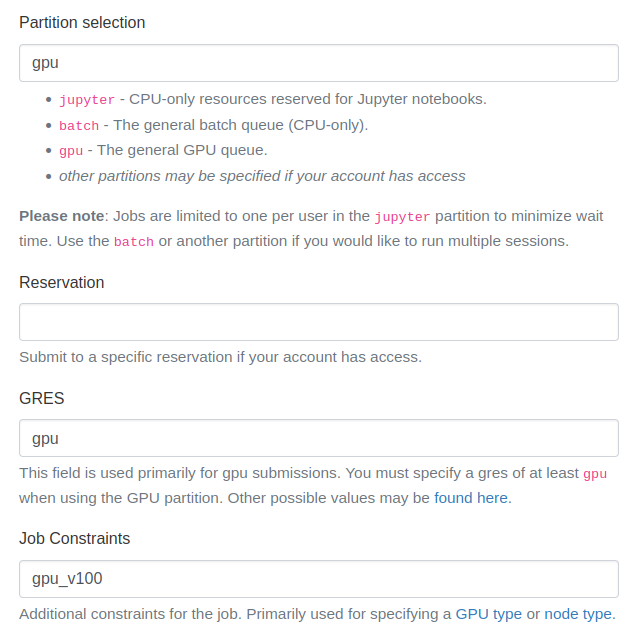
In HCC Open OnDemand, you can request GPU resources by specifying the resource you want to use in the Job Constraints section when requesting resources. For example, when looking at the options in the Available GPUs section, we can choose Partition Selection and GRES values of "gpu" and then a Job Constraints value of "gpu_v100" to request the "Tesla V100, with 10GbE" GPU.
Compiling¶
Compilation of CUDA or OpenACC jobs must be performed on the GPU nodes.
Therefore, you must run an interactive job
to compile. An example command to compile in the gpu partition could be:
$ srun --partition=gpu --gres=gpu --mem=4gb --ntasks-per-node=2 --nodes=1 --pty $SHELL
The above command will start a shell on a GPU node with 2 cores and 4GB of RAM in order to compile a GPU job. The above command could also be useful if you want to run a test GPU job interactively.
Submitting Jobs¶
CUDA and OpenACC submissions require running on GPU nodes.
cuda.submit
#!/bin/bash
#SBATCH --time=03:15:00
#SBATCH --mem-per-cpu=1024
#SBATCH --job-name=cuda
#SBATCH --partition=gpu
#SBATCH --gres=gpu
#SBATCH --error=/work/[groupname]/[username]/job.%J.err
#SBATCH --output=/work/[groupname]/[username]/job.%J.out
module load cuda
./cuda-app.exe
OpenACC submissions require loading the PGI compiler (which is currently required to compile as well).
openacc.submit
#!/bin/bash
#SBATCH --time=03:15:00
#SBATCH --mem-per-cpu=1024
#SBATCH --job-name=cuda-acc
#SBATCH --partition=gpu
#SBATCH --gres=gpu
#SBATCH --error=/work/[groupname]/[username]/job.%J.err
#SBATCH --output=/work/[groupname]/[username]/job.%J.out
module load cuda/8.0 compiler/pgi/16
./acc-app.exe
Submitting Pre-emptable Jobs¶
Some GPU hardware is reserved by various groups for priority access. While the group that has purchased the priority access will always have immediate access, HCC makes these nodes available opportunistically. When not otherwise utilized, jobs can run on these resources with the limitation that they may be pre-empted (i.e. killed) at any time.
To submit jobs to these resources, add the following to your srun or sbatch command:
--partition=guest_gpu --gres=gpu
In order to properly utilize pre-emptable resources, your job must be able to support some type of checkpoint/resume functionality.