Introduction to HPC
What is HPC
High-Performance Computing (HPC) is the use of groups of computers to solve computations a user or group would not be able to solve in a reasonable time-frame on their own desktop or laptop. This is often achieved by splitting one large job amongst numerous cores or ‘workers’. This is similar to how a skyscraper is built by numerous individuals rather than a single person. Many fields take advantage of HPC including bioinformatics, chemistry, materials engineering, and newer fields such as educational psychology and philosophy.
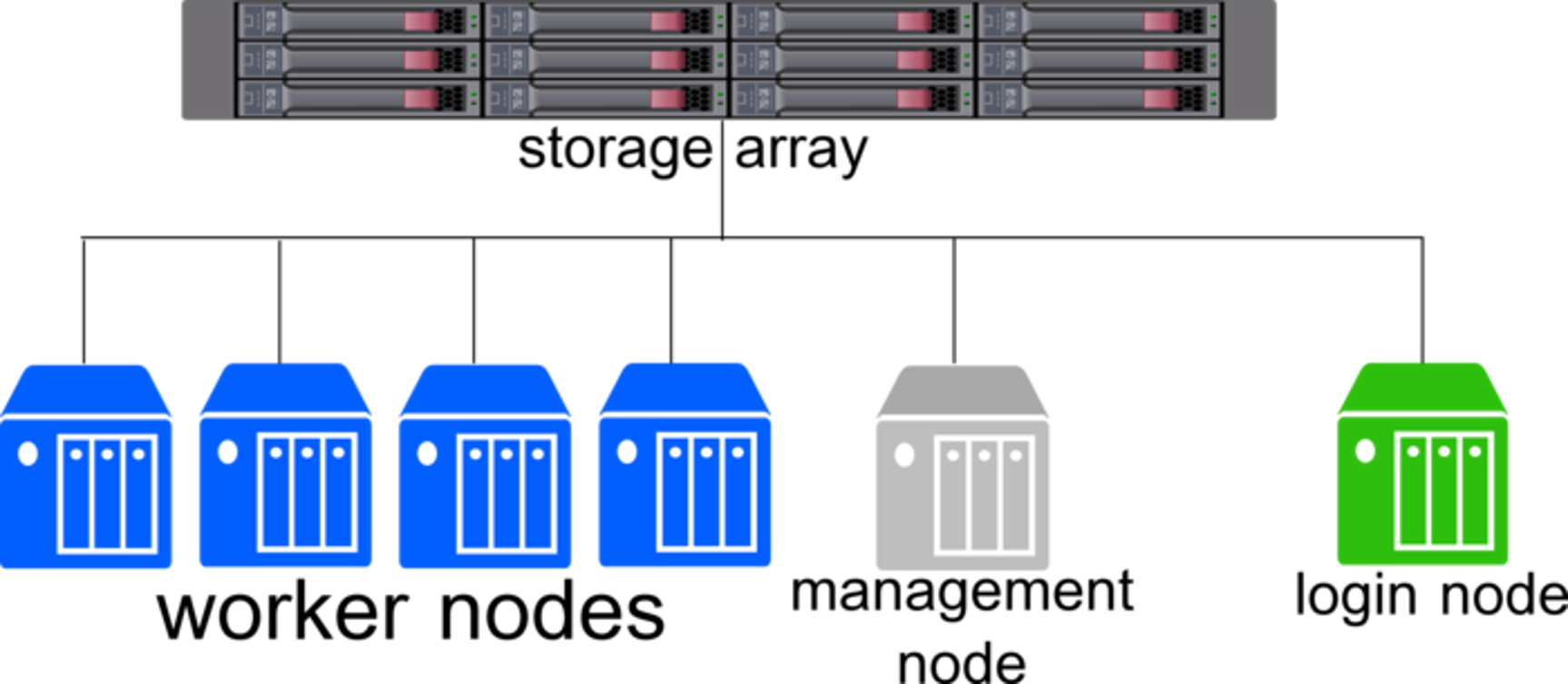
HPC clusters consist of four primary parts, the login node, management node, workers, and a central storage array. All of these parts are bound together with a scheduler such as HTCondor or SLURM.
Login Node:
Users will automatically land on the login node when they log in to the clusters. You will submit jobs using one of the schedulers and pull the results of your jobs. Any jobs running on the login node directly will be stopped so others can use the login node to submit jobs.
Management Node:
The management node does as it sounds, it manages the cluster and provides a central point to manage the rest of the systems.
Worker Nodes:
The worker nodes are what run and process your jobs that are submitted from the schedulers. Through the use of the schedulers, more work can be efficiently done by squeezing in all jobs possible for the resources requested throughout the nodes. They also allow for fair use computing by making sure one user or group is not using the entire cluster at once and allowing others to use the clusters.
Central Storage Array:
The central storage array allows all of the nodes within the cluster to have access to the same files without needing to transfer them around. HCC has three arrays mounted on the clusters with more details here.